Back during the 2020 Democratic Primary, I co-organized the official Tech for Warren volunteer group. We worked on a number of projects, including red teaming one of the campaign’s applications, and my favorite by far was the Warren Plan Bot, a reddit bot on /r/ElizabethWarren who answered questions about Senator Warren’s signature plans.
Of course, a lot has changed since then, and I’ve been curious how I might do things differently today, so I decided to give it a once-over. To get right to that AI climax, jump to: in 2023, bot plans you. Spoiler alert: I used LLMs.
What, exactly, is a “Plan Bot?”
The idea for the Warren Plan Bot was proposed by my collaborator Shane Ham, inspired by the various Wikipedia response bots that live on Reddit. While our bot could do a handful of plan-related things, its most popular feature was plan matching, which worked like this
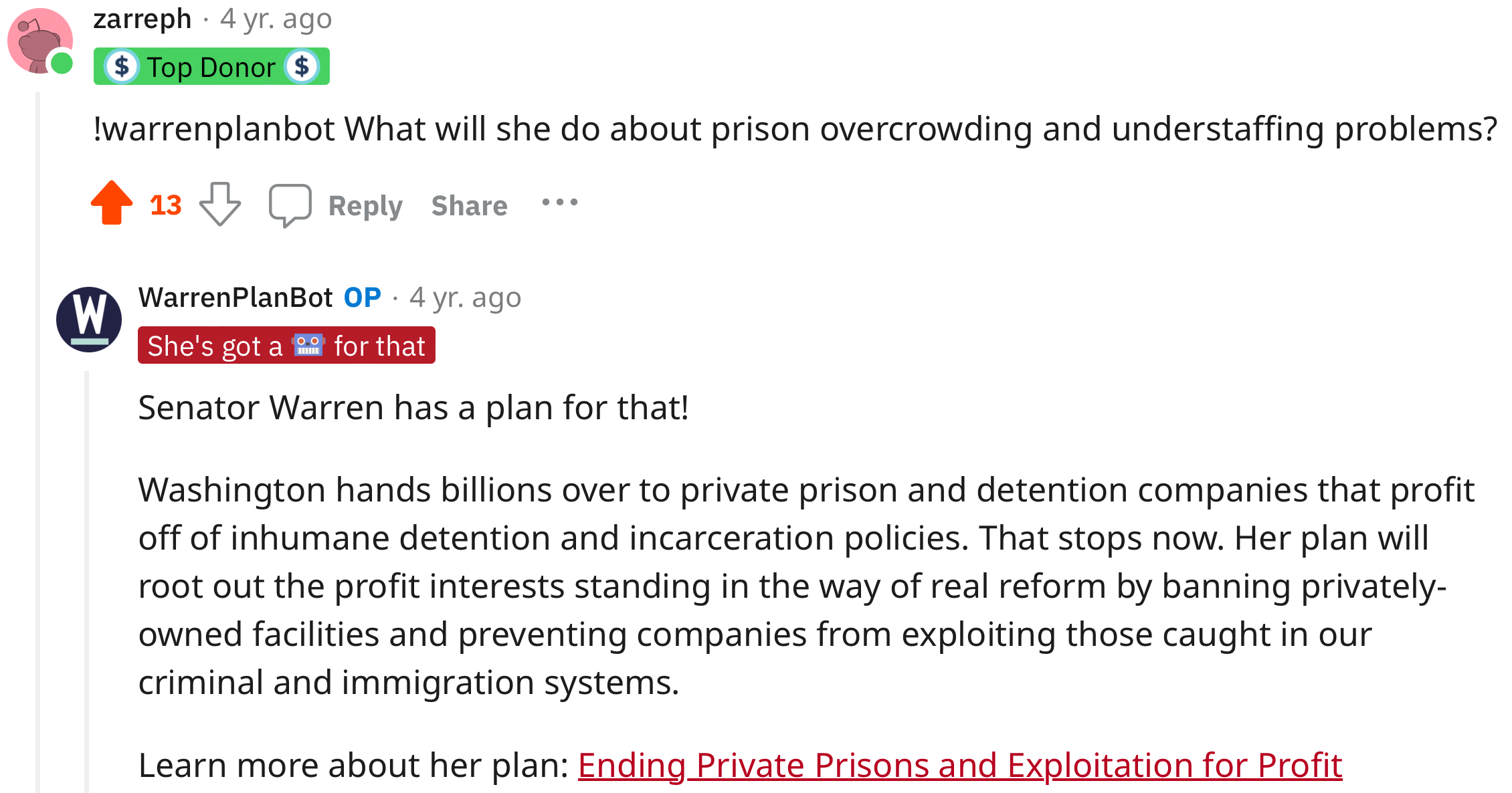
Redditors liked it! Mods and other power users were often fielding questions from the Warren-curious, and calling in the bot saved time and added some playfulness to the overall chaos and excitement. Here’s some of the early feedback
What is a Plan Bot made of? Technically speaking
Below is the architecture of the Warren Plan Bot
 We hosted this on Google Cloud. My professional work is generally on AWS and it’s nice to keep things fresh.
We hosted this on Google Cloud. My professional work is generally on AWS and it’s nice to keep things fresh.
A great thing about this architecture is how reliable it is. It has been running, forgotten, the past 3 years with zero intervention, deterred only by Reddit’s recent API changes which broke our original search engine, Pushshift. It is also easy to control costs. It cost a $1/day across dev & prod while running constantly, but after the campaign, I dialed down the frequency to hourly, and the cost went to zero. Everything is managed in Terraform, so changes are easy to make.
How does it know what plans a user wants?
Because Redditors might use a variety of words when searching for a plan, matching them is a fun NLP challenge.
Starting simple
A principle I learned from my co-workers at Manifold is to start with the simplest model possible to provide a baseline against which to compare fancier techniques.
For our simple version, we did fuzzy string matching, using fuzzywuzzy, to compare users’ posts against handwritten topics.
>>> fuzz.token_sort_ratio("climate change", "climate change")
100
>>> fuzz.token_sort_ratio("climate change", "climate crisis")
50
>>> fuzz.token_sort_ratio("climate change", "medicare for all")
20
This unsurprisingly didn’t work all that well, so we decided to invest in something smarter.
Keeping score
We first built a scoring framework to evaluate potential matching techniques. We started by labeling synthetic posts with desired matches, and as folks used the plan bot in the wild, we continuously augmented that with real posts.
# scoring weights
CORRECT_MATCH = 1
ALTERNATE_MATCH = 0.5
NO_MATCH = 0
WRONG_MATCH = -2
// labeled_posts.json
[
{
"text": "!warrenplanbot what is her plan to invest in public education?",
"source": "/r/ElizabethWarren",
"match": "public_education",
"alternate_matches": [
"affordable_higher_education",
"universal_child_care"
]
},
{
"text": "!warrenplanbot lobbying",
"source": "/r/ElizabethWarren",
"match": "excessive_lobbying_tax"
},
…
]
Matching the plans
The approach that won the day was TF-IDF followed by LSA. While these techniques lack the broader language-awareness of methods like embeddings, they are simple and explainable, and worked reasonably well for our task. They leverage statistics about how words occur in the documents under consideration – in this case, Senator Warren’s plans - in order to best differentiate them.
-- Matching Strategy Scores (out of 100) --
lsa_gensim_v3: 87.1
tfidf_gensim_v3: 80.8
token_sort_ratio: 16.2
Bag of Words
Our models were trained on the full text of the plans (scraped from the website, and cleaned up using beautifulsoup). We preprocessed with basic stemming and stripping, removed stopwords, and added both words and bigrams (pairs of consecutive words) into our initial bag of n-grams representation.
| Climate Plan | Child Care Plan | Wealth Tax Plan | |
|---|---|---|---|
| “Climate” | 6 | 0 | 0 |
| “Wealth” | 0 | 1 | 3 |
| “Plan” | 4 | 2 | 1 |
This chart shows a toy example of word occurrences within each plan, where each column represents a “bag of words”.
In some cases, we also added additional text to a plan to improve matching or include a synonym. For example, the plan “Protecting Our Public Lands” mentioned protecting public lands from being sold to oil and gas, but it didn’t mention “fracking” by name. Overall, the plans are long and detailed, so this was relatively rare.
TF-IDF
Next, we applied TF-IDF (Term Frequency–Inverse Document Frequency) using the Gensim topic modeling package. TF-IDF relies on the notion that words occuring in only a few plans are helpful for distinguishing them, while words that occur in many or all plans are not differentiators.
If you’re spatially minded, you can think of this as a scaling operation. Dimensions representing rare words stretch larger, and those representing common words shrink.
| Climate Plan | Child Care Plan | Wealth Tax Plan | |
|---|---|---|---|
| “Climate” | 9 | 0 | 0 |
| “Wealth” | 0 | 2 | 5 |
| “Plan” | 0 | 0 | 0 |
Continuing with our toy example, we see that the word “climate” is somewhat rare, and so all “climate” counts scaled larger. On the other hand, the word “plan” occurs in every plan, and so those are completely zeroed.
Latent Semantic Analysis
While TF-IDF got us most of the way there, to make things a little better still, we next applied LSA (Latent Semantic Analysis). The idea behind LSA is that words which are similar in meaning tend to occur together, forming “topics.” This is a nice property to leverage, because we want to retrieve a plan similar in topic to a user’s post, not simply one that overlaps in the exact words used. The spatial intuition is tougher here, but take a look at singular value decomposition if you want to get a sense.
The LSA step results in a number of topics, which represent a new dimensional space in which to map each plan.
$$ \text{Topic}_{\text{green energy?}} = 0.29* \text{“energy”}+ 0.28* \text{“climate”}+ 0.22* \text{“emission”} + 0.17* \text{“green”} + \ldots $$
$$ \text{Topic}_{\text{defense?}} = 0.19* \text{“defense”} + 0.17* \text{“pentagon”} + 0.16* \text{“military”} - 0.44* \text{“farmer”} + \ldots $$
$$ \text{Topic}_{\text{healthcare?}} = 0.18* \text{“health”} + 0.15* \text{“disability”} - 0.40* \text{“farmer”} - 0.20* \text{“tech”} + \ldots $$ Here are the top 3 topics in our model, with my interpretation of what each topic might “represent”
We map all the full-text documents, as well as the titles of the plans and a set of handwritten topics, into the dimensional space represented by these topics.
The Matching Step
Finally, we’re ready for matching. When a user makes a post, we preprocess it and then map it into this same dimensional space.
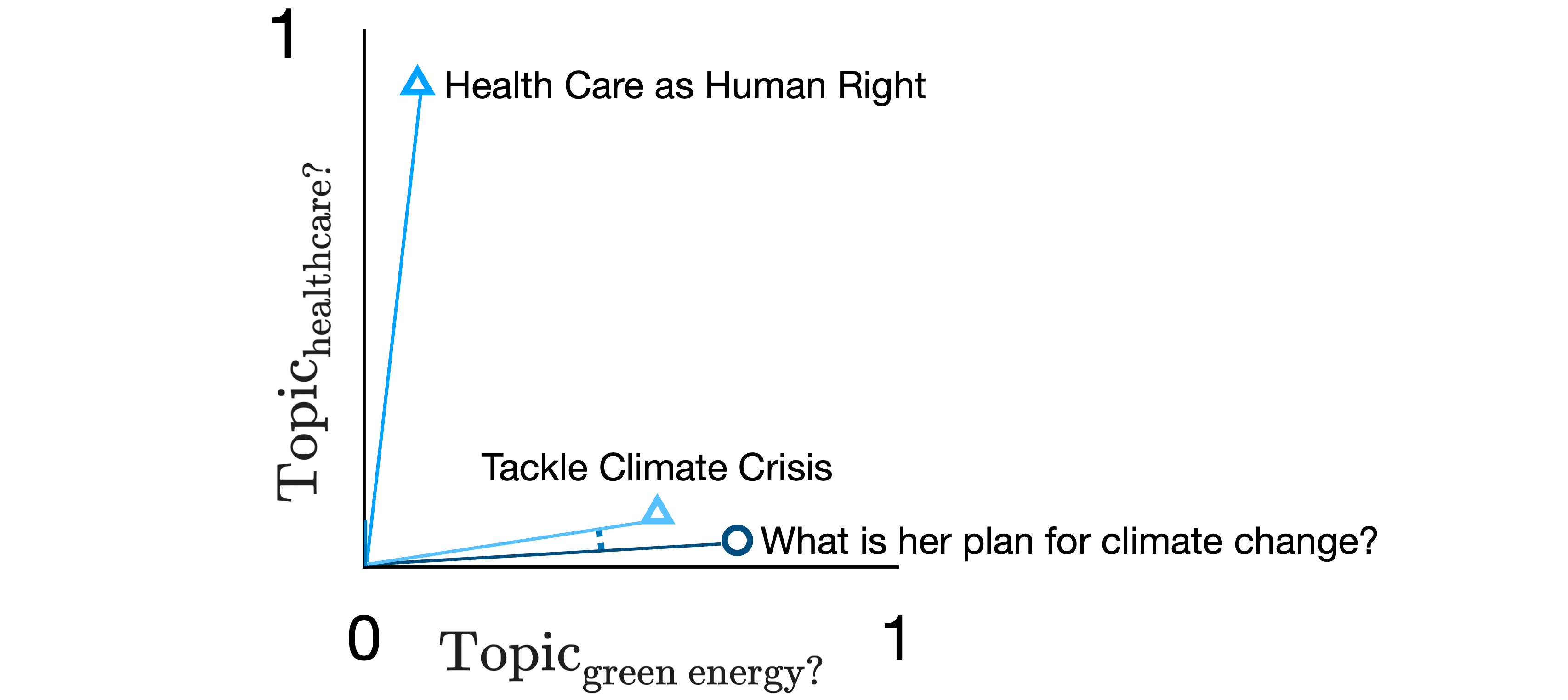 Whichever plan (or title or handwritten topic) is closest to the user’s post we consider to be the best match.
Whichever plan (or title or handwritten topic) is closest to the user’s post we consider to be the best match.
Time to Reply
If that distance is smaller than a certain threshold, we reply with a summary of the plan, drawn from the campaign website.

And if not we share our best guesses.
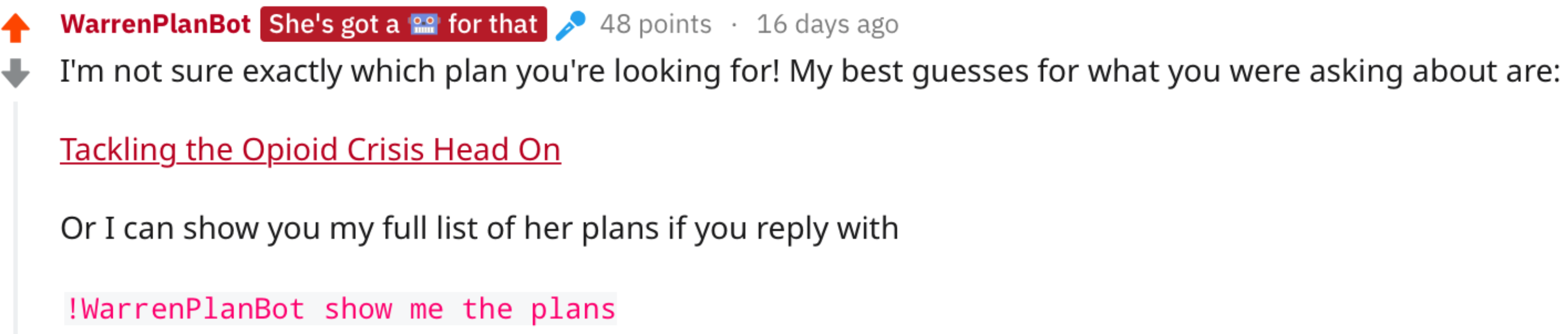
Good bot.
In 2023, Bot Plans You
There have been, it’s safe to say, some changes in the world since we first built the Plan Bot. Notably, the rise of generative AI, in particular the advent of Large Language Models (LLMs), appears to have changed the game practically overnight. LLMs are especially powerful because, as it turns out, language is a deeply rich and flexible medium of communication. Simply by accepting a text prompt and performing what is effectively an incredibly complex “auto-complete”, LLMs can achieve meaningful language tasks like answering questions, telling stories, suggesting recipes, and even writing non-trivial code.
What this means for my day job is that literally any tedious coding task goes first to ChatGPT.
What it means for our Plan Bot is that with a credit card and few extra lines of code, it will not only match plans, but also answer detailed questions about them!
But before we get too excited, not everything is sunshine and roses. The current generation of LLMs have a few notable problems:
- They tend to hallucinate
- They don’t know anything about the past two years
This doesn’t seem like a great start for a robot campaign representative.
Retrieval Augmented Generation
Fortunately, there’s a solution. Rather than relying on an LLMs existing knowledge, we explicitly provide the relevant information for answering a question. This is especially important for a political campaign, where information found elsewhere on the internet could easily be from political opponents. This is called Retrieval-Augmented Generation (RAG).
The RAG model also works within another key limitation of LLMs:
- They only accept a limited amount of new information (known as the “token limit”)
So before handing things off to an LLM, a different process must be used to “retrieve” the most relevant information.
Retrieval
Modern RAG pipelines typically leverage embeddings in the retrieval step. Early experiments for matching plans using embeddings were promising, as you can see in the matching scores below, but it would take some time to get right, so that’s a topic for a future post.
-- Matching Strategy Scores (out of 100) --
lsa_gensim_v3: 87.1
tfidf_gensim_v3: 80.8
ada_embeddings: 47.5
Fortunately, the first version of the Plan Bot already retrieves plans! For now, we can move right to response generation.
Prompt engineering
To generate our response using an LLM, we perform “prompt engineering”, generating text for our LLM tailored to our specific task.
First, we prepare a “system prompt” to tell the LLM who it “is”:
You are the WarrenPlanBot, an expert Reddit bot that is trusted around the world to answer questions about Senator Warren's plans.
You are kind and optimistic, and support Elizabeth Warren for president.
Always answer the query using the provided context information, and not prior knowledge.
And to make sure the answers aren’t stilted or too short, we tell it:
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or 'the relevant plan' or anything along those lines.
3. Include information about the plan provided in the given context
These are all heavily inspired by the LlamaIndex default prompts
Next we bring in the information we’ve retrieved via a “user prompt”. Here, we provide the exact plan to draw on, and again remind the LLM not to use any outside knowledge. To the extent possible, all the information guiding the answer will be coming straight from the campaign. At end of this set up, we finally ask it our question.
Context information is below.
---------------------
The title of Senator Warren's plan: "{plan['display_title']}"
A summary of this plan: {plan['summary']}
The full text of this plan:
{plan['full_text']}
-----------
Given the context information and not prior knowledge, answer the question.
Query: {user_input}
Answer:
----
This is Python string interpolation, so all the “{}” would be filled in ahead of time
Having created our prompts, we simply send them to the OpenAI API and wait for a response. It only takes a couple seconds.
llm_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k", # Need at least 12k tokens in order to fit largest plans
messages=messages,
temperature=0, # consistent responses are more desirable than creative responses for a political campaign
)
To limit the possibility of the LLM hallucinating, we’ll keep our earlier interaction model of a single post and reply (rather than a full conversation).
The overall flow looks like this:

Success!
We can now answer a user’s questions about a plan.
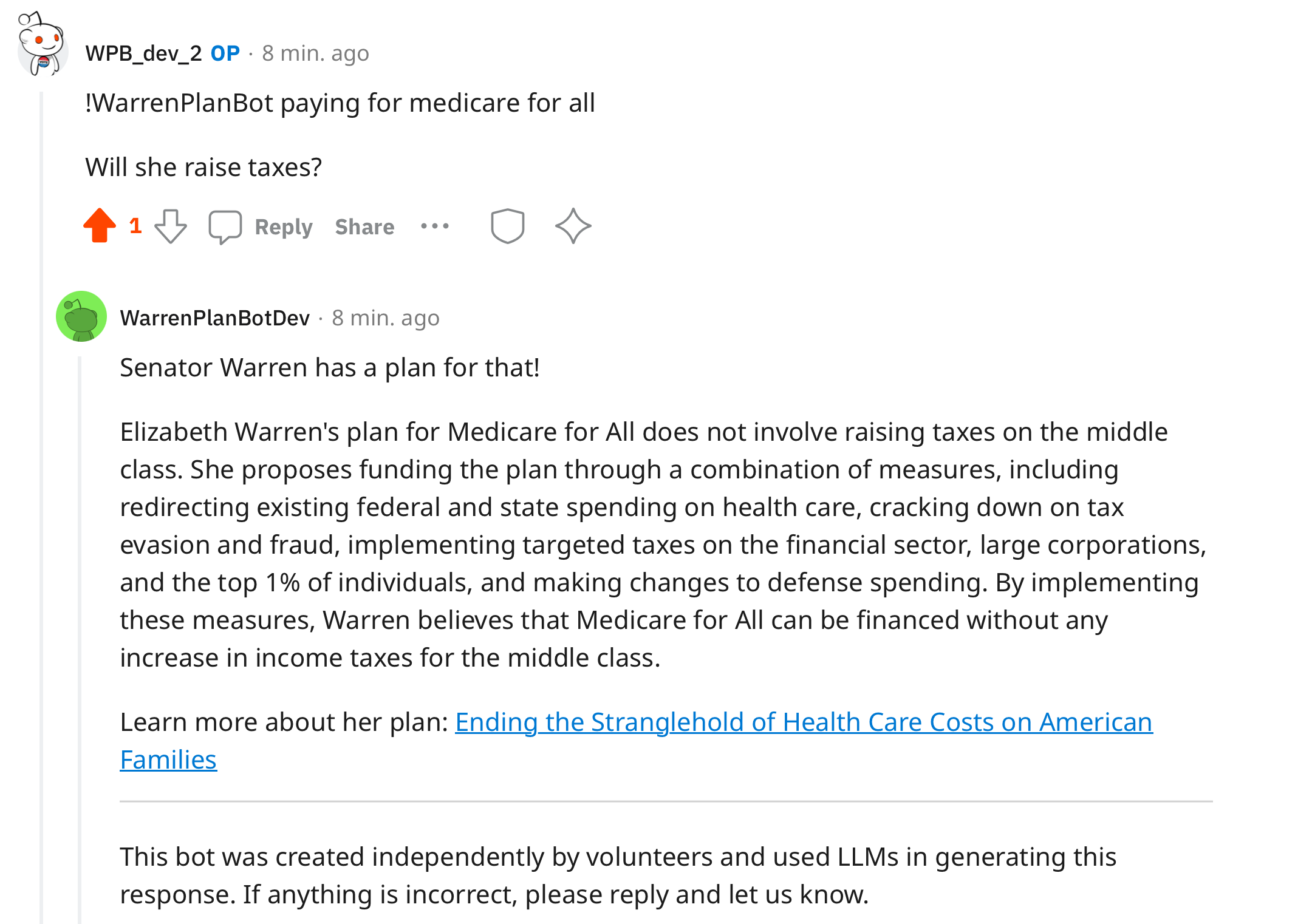 Spoken like a true politician.
Spoken like a true politician.
Stayin’ Alive
So with a shiny new coat of AI, the WarrenPlanBot lives on a little longer. Truth be told, there hasn’t been much call for information about Elizabeth Warren’s presidential campaign proposals the past few years, but if you’d like, you can still find it over on /r/WPBSandbox. Take it for a spin why not – match a plan, ask a question even.
You can also see all the code that makes it possible over in the repo.
Team
A number of collaborators were critical in making the first version of this bot happen
- Shane Ham, project co-lead
- Osei Poku & Rob Jones, contributing developers
- Matyas Tamas, advisor on NLP methods and packages
- Andrea Flores, co-organizer of Tech for Warren
- Everyone else in the Tech for Warren group for working toward big, structural change
Until next time.